
事件经过
某天,收到了风控中心的一则通报…详情如下:
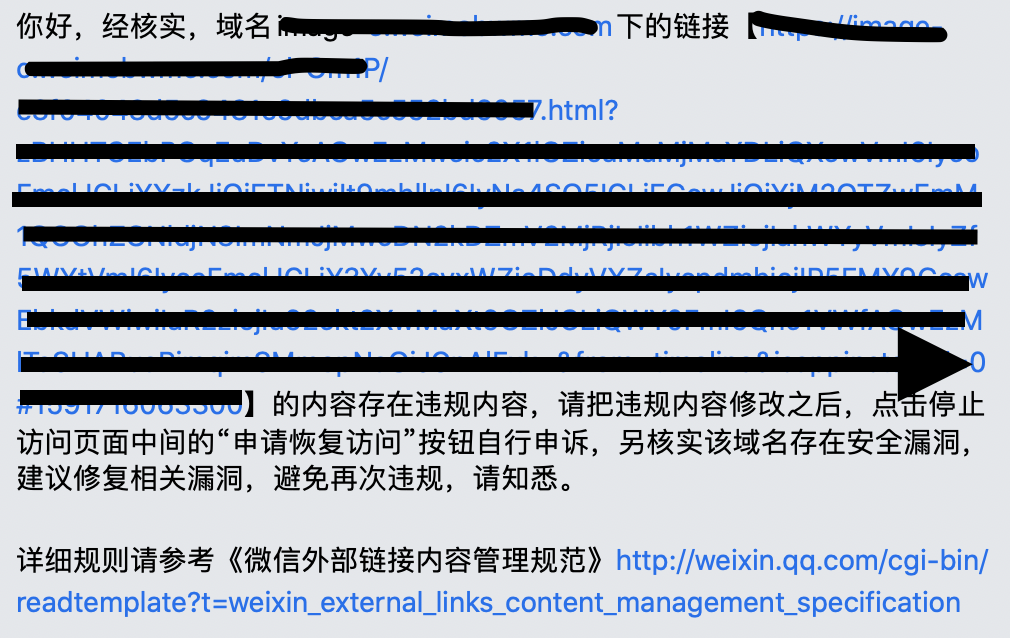
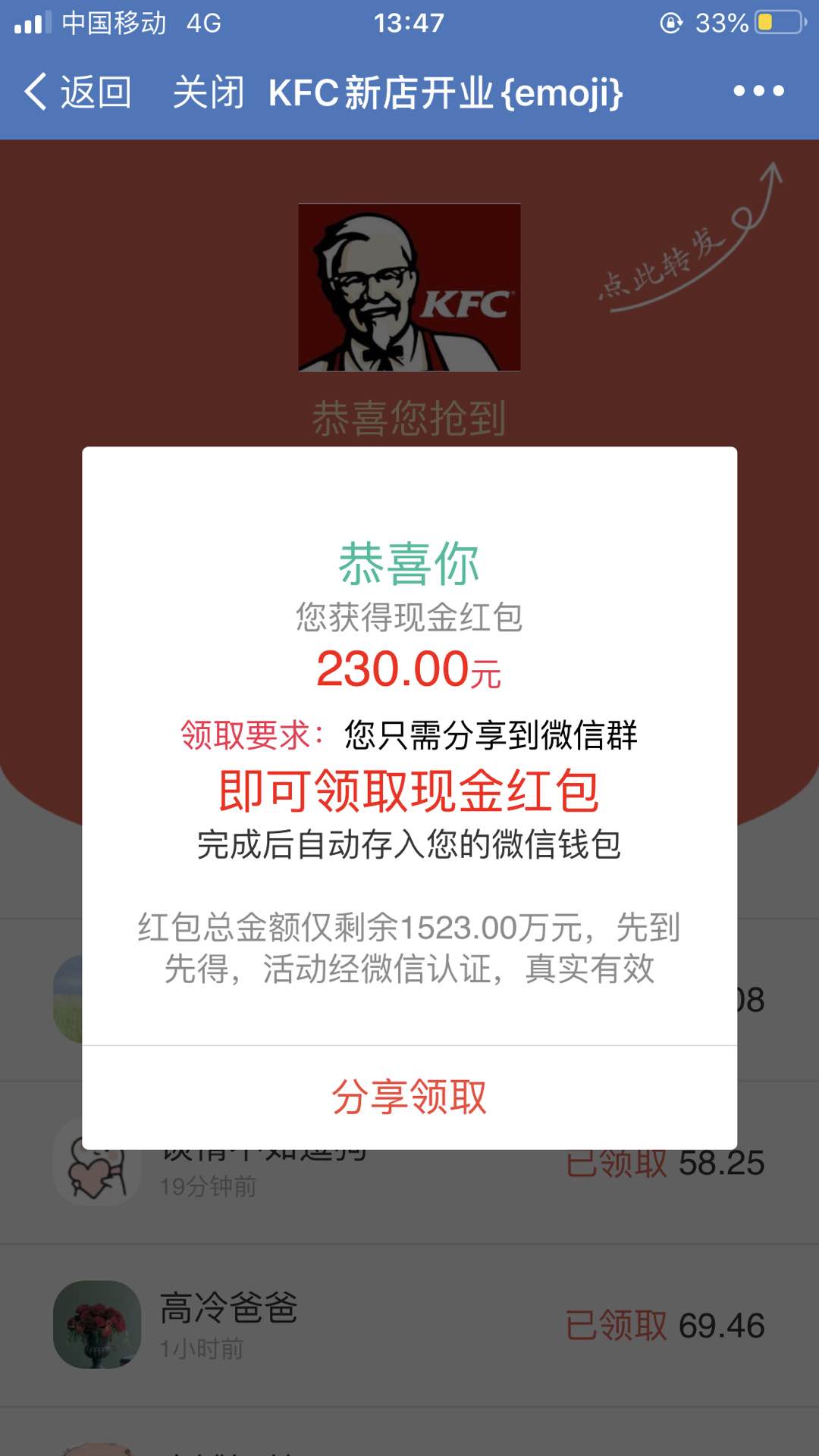
用手机打开发现是假红包233…

事件处理
用浏览器访问该链接可以直接下载,下载后打开html,内容如下:
1 | <html lang="en"><head><meta charset="UTF-8"><title></title></head><body><span><span><script src="//b.46.si"></script></body></html> |
显然加了跳转,用户访问即会跳转到假红包界面。
我们的文件是统一上传到文件中心的,没有对html文件做限制,因此产生了此问题,问题产生了就得解决。
显然限制html文件的上传是行不通的,这可能会对某些业务造成影响。
将文件中心的URL列表下载下来进行分析处理
需求为:筛选出html后缀的URL,并对html的文件内容进行处理:将html文件中所有src标签里的内容进行列举出来,最后将URL和内容写入新的文件中
1 | # coding=utf-8 |
然后还在发现有啥特征…233
后续工作
若找到规律后,会对该特征进行自动化的检测,然后放到服务器上,对用户上传的html文件进行自动化的检测。