
内容一般分为两部分,非结构化的数据 和 结构化的数据。非结构化数据:先有数据,再有结构,比如文本、电话号码、邮箱地址(利用正则表达式处理)、HTML 文件(利用正则、XPath、CSS选择器)结构化数据:先有结构、再有数据,比如JSON(JSON Path)/XML (Xpath/正则等)
不同类型的数据,需要采用不同的方式来处理。
爬虫一共就四个主要步骤:
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
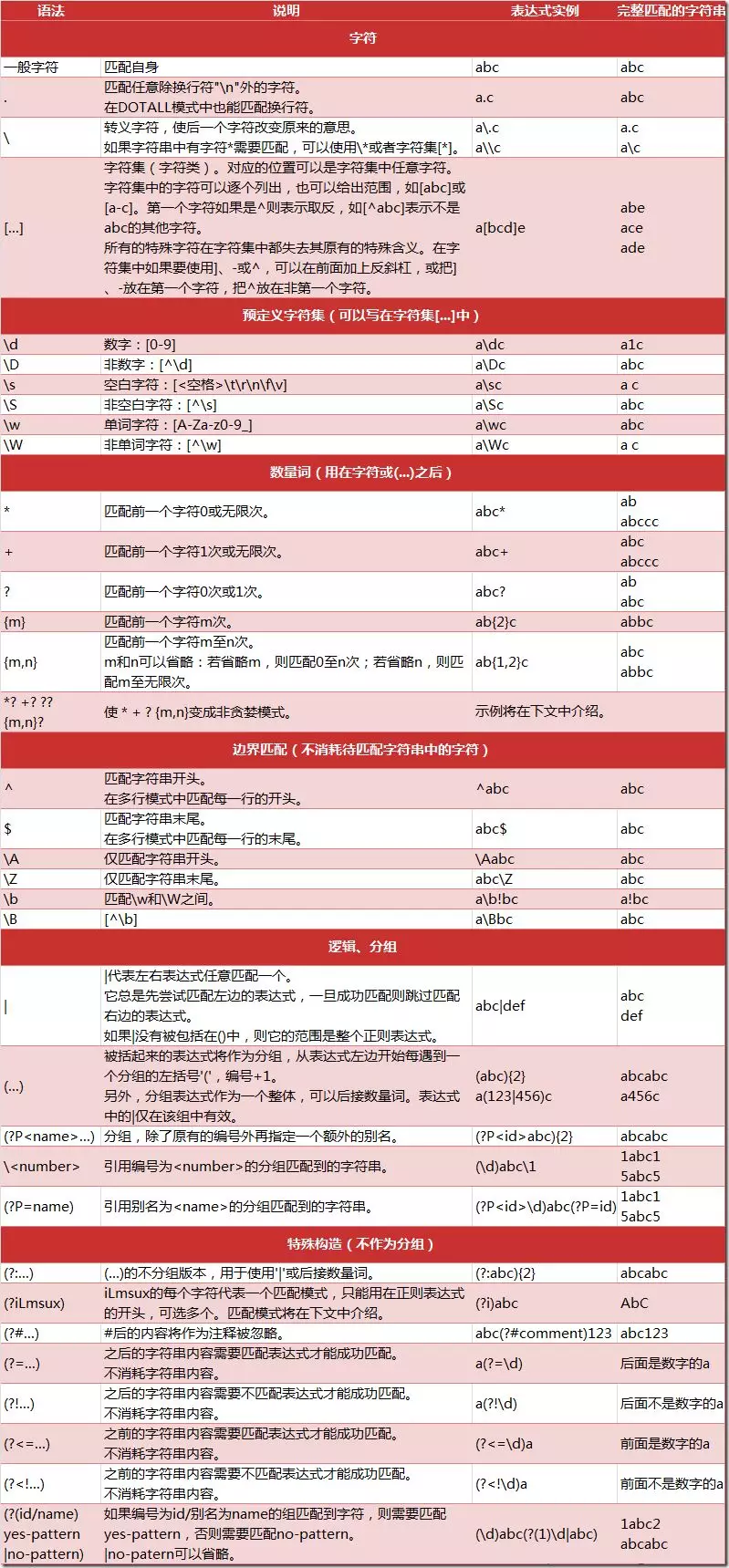
正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
在任何编程语言中都有正则表达式,JS、JAVA、C#等等多有,Python 自1.5版本起增加了re 模块,re 模块使 Python 语言拥有全部的正则表达式功能。
正则匹配的规则
re模块使用步骤
在 Python 中,可以使用内置的 re 模块来使用正则表达式
正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,示例:r’testt.tpython’
re 模块的一般使用步骤如下:
- 1.使用
compile()函数将正则表达式的字符串形式编译为一个 Pattern 对象 - 2.通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。 - 3.最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作
例子:
1 | import re |
1 | import re |
\d匹配任何十进制数,它相当于类[0-9],只返回一位数字\d+\d+如果需要匹配一位或者多位数的数字时用,返回多位数字
compile() 函数将正则表达式的字符串形式编译为一个 Pattern 对象,Pattern 对象提供的一系列方法对文本进行匹配查找,来罗列下方法:
m.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None。
1 | import re |
m.findall遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表。
1 | import re |
m.match决定RE是否在字符串刚开始的位置匹配
1 | import re |
m.split()按照能够匹配的子串将string分割后返回列表
1 | import re |
m.sub()使用re替换string中每一个匹配的子串后返回替换后的字符串
1 | import re |